
Amsat-UK's Oscar News, 1990 Feb No.81 p.11-15
SHANNON, CODING AND THE RADIO AMATEUR
by
James Miller G3RUH
In a previous Oscar News (ref 1,8) I described the error detection and
correction (EDAC) of Oscar-13's computer memory. I showed how the simple
addition of a few redundant "parity bits" to each data byte achieved this,
and ended by noting that this technique is used to increase data
transmission reliability. That is, you send more bits than you started
with, so for a fixed transmitter power the intrinsic bit error rate
worsens. However the error correction scheme more than makes up for this,
a result which seems to defy intuition, but which is the justifiable
substance of C E Shannon's famous coding theorems. (ref 2)
We are not in the realms of academia here. When space communication costs
are reckoned in millions of $$$ per db (ref 4), schemes that provide more
bytes for your buck are of the greatest importance. Their use in amateur
radio isn't far away. Intrigued? This article is a brief introduction.
A BASELINE SYSTEM
Lets explore; first of all we look at the standard baseline system, binary
PSK transmission. That is to say, a 0 is sent by a carrier with phase 0
degrees, and a 1 by phase 180 degrees, i.e inverted. The optimum
demodulator (PSK decoder) processes the received carrier to detect a 1 or 0.
For our baseline assessment we need to draw a graph of the probability of a
bit error as a function of signal-to-noise ratio (SNR) for binary PSK.
Look at figure 1. The vertical axis is "Pe" for probability of error. For
example Pe=0.01 means 1 error per 100 bits. Pe=10^-6 means one in a
million bits, which is a pretty small chance. Horizontal is "Eb/No" which
stands for Energy-per-bit per Noise-power-per-Hz-bandwidth. (This is the
same as SNR when the bit rate is the same as the bandwidth). You can see
in the various curves that a higher SNR results in a smaller error rate.
Curve A shows the baseline PSK performance. At poor SNR the error rate
is, not suprisingly, 50%. However by 7 db SNR it's down to 1 per 1000, and
at 9.6 db about 1 in 100,000 bits.
For reference, the mathematical equation for curve A is given by:
Pe = 0.5*erfc(sqr(Eb/No)) where erfc(.) is the complementary error
function, and sqr(.) is square root. Erfc(.) is related to the cumulative
Gaussian distribution, and is tabulated in mathematical and statistical
handbooks (ref 3). Typical values: erfc(0)=1.0, erfc(0.5)=0.48,
erfc(1)=0.14, erfc(1.5)=0.034, erfc(2)=0.005, etc, tending to zero.
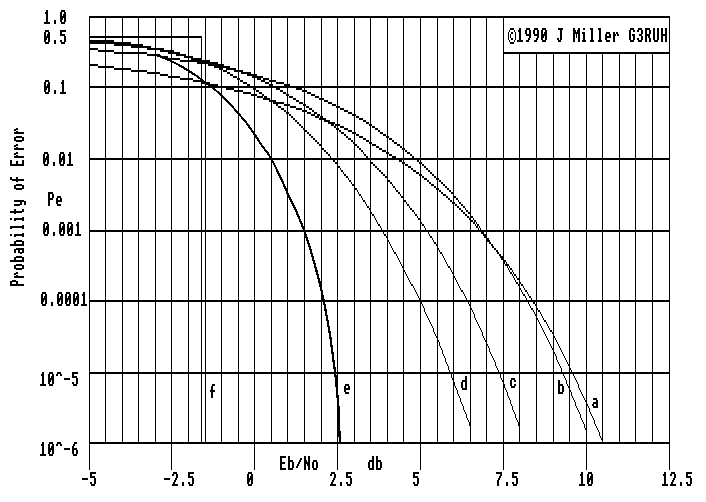 Figure 1. Performance comparison of various channel coding schemes
A. Baseline: Binary PSK
B. (7,4) Hamming coding, hard decisions
C. (7,4) Hamming coding, soft decisions
D. Mariner '69 deep space probe, (32,6) bi-orthogonal coding
E. Voyager probes, NASA deep space standard (ref 6)
F. Theoretical Shannon limit on coding performance.
[ Added: In 2004 I discovered this Xilinx paper page 4.
[ Pirate copy - though admittedly pretty!]
HAMMING CODING
Now what happens when we add parity bits? Lets examine a specific
arrangement, the (7,4) Hamming code. In this, data is taken 4 bits at a
time and 3 parity bits appended to make a "word" of 7 bits, hence the
designation (7,4). I used this as my example in ref 1. Denoting the data
bits D0, D1, D2, D3, the parity bits are formed from excusive-ORs of the
data bits, viz: P0=D0+D1+D3, P1=D0+D2+D3, P2=D1+D2+D3. The 16 possible
words are thus (with a little space for clarity):
DDDD PPP DDDD PPP DDDD PPP DDDD PPP
3210 210 3210 210 3210 210 3210 210
--------------------------------------------------
0000 000 0100 110 1000 111 1100 001
0001 011 0101 101 1001 100 1101 010
0010 101 0110 011 1010 010 1110 100
0011 110 0111 000 1011 001 1111 111
--------------------------------------------------
Table 1. 16 code words of the (7,4) Hamming code
--------
So as an example, if the 4 data bits are 1100, P2=0, P1=0 and P0=1, so the
bits actually transmitted are 1100001 - see top of 4th column.
Consider transmission; we now send 7 bits in the time we would have sent 4
original ones. So the channel bit rate is 7/4 times what it was, implying
a 7/4x wider bandwidth.
Now reception; for the same transmitter power as used in the baseline
system, the received Eb/No must be 4/7 worse, leading to a higher error
rate for the 7 bits of the word. But the Hamming coding scheme allows
correction of up to 1 error. So words with 0 or 1 error are OK, words
with 2,3...7 errors are bad. Thus the probability of a word error is Pw =
p2+p3+p4+p5+p6+p7 = 1-(p0+p1), where p0 is the probability of nil errors,
p1 for 1 error and so on. When we get a word error, its data bits are
essentially garbage, i.e 50% are in error. So the equivalent bit error rate
for the system is approximately Pe=Pw/2 (actually 4/7*Pw).
Curve B of figure 1 shows the performance of the (7,4) Hamming code using
"Hard" decisions as described above, where the 7 elements of the word are
demodulated individually and independently. At an SNR less than 7.5 db
the baseline PSK system is a better performer, but above this SNR the
Hamming code wins. The gain is equivalent to 0.4 db in SNR at an error
rate of 1 per million.
CODING GAIN
Not dramatic, but it illustrates the point. We have achieved a
"coding gain" of 0.4 db at the expense of a) increased bandwidth,
b) increased decoder complexity and c) throughput delay.
This gain can be used either to a) reduce transmitter power or antenna
sizes by 0.4 db, or b) increase the data rate by 10%, or c) increase
communication range by 5%.
For reference, curve B is computed from the formulae:
p=0.5*erfc(sqr(4/7*Eb/No)), Pw=1-((1-p)7 + 7*p*(1-p)6), and Pe=Pw*4/7.
OPTIMUM DECODING
There is a better way to decode the 7 bit words. Instead
of demodulating them as 7 individual bits ("hard" decisions), we can
demodulate the whole word using 16 detectors individually matched to the 16
patterns in table 1. Then the detector showing the highest output or
"correlation" is chosen as correct and the associated 4 data bits are
output. This is called "soft" decision decoding. These detectors would
almost certainly not be mechanised in hardware, as there are so many of
them. It is far simpler to do the equivalent operations in software -
digital signal processing (DSP), though this need not concern us here; we
assume the job done somehow.
The performance of this new scheme, in which we appear to have forgotten
Hamming's error detection scheme, is shown in curve C of figure 1.
Compared with the baseline PSK, we have an improvement or coding gain of 2.
4 db at a bit error rate of 1 in a million. Now we're getting somewhere!
It's interesting to note that the performance difference between hard and
soft decision decoding, exemplified by this simple scheme, is just 2 db.
This hard/soft penalty, 10*log(PI/2), shows up regularly in signal
processing analysis, regardless of coding scheme, in the power-constrained
situation.
And no, we haven't really lost Mr Hamming. Remember there are 7 bits to
the word; that means a potential 128 combinations of bits, from which we
chose only 16. Not any 16, but a set in which each code-word is as
different as possible from each other word. Hamming's code achieves this,
as in fact do several other sub-sets.
MARINER '69 MARS PROBE
Mariner '69 Mars probe was one of the first missions to make use of coding.
Why? Because at vast distances, with limited transmitter power, a finite
antenna size on the spacecraft and on the ground, every fraction of a
decibel counts. Mariner '69 used a (32,6) code, in which blocks of 6 bits
were augmented to make a 32 bit word, a bandwidth expansion of 32/6 or 5.
3:1. Detection was by soft decisions using correlators. The performance is
shown in curve D of figure 1. The coding gain is about 3.6 db at an
error rate of 1 per million bits.
SOURCE CODING
Space probes typically send back images. However images are usually full
of redundant information. For example a picture that includes a horizon
might contain large areas of blackness. It would be a folly to send back
such an image without pre-processing.
The business of efficient representation of information is called "source
coding", as distinct from channel coding discussed so far. In many
applications, source coding is likely to have a far greater influence on
overall communications efficiency than channel coding, yet it is often
overlooked or simply ignored.
A good example is amateur spacecraft telemetry, where data is sent down
block after block, with little or no change in some of the data, but rapid
changes in others. So it's efficient for some information, but not all.
Another is plain language bulletins. When I checked a sample of 50 Oscar-
13 message blocks I found that based on the frequency of occurence of
letters/digits etc, the average Information content was less than 5
bits/character; yet we actually transmit bulletins with 8 physical
bits/character.
The most common symbol was 'space'. Clearly it could be represented by one
bit only, say 0. Next came the letter 'e', so it should be recoded as 10,
and so on. This kind of scheme is Huffman coding, an algorithm for the
construction of efficient signalling alphabets. In my example a saving of
5/8 in bits or 2 db would be achieved at the expense of a look-up table in
the spacecraft, and a similar algorithm at the receiver.
CONVOLUTIONAL CODING
Returning to the subject of channel coding; the schemes outlined thus far
are examples of "Block Coding", because data is transmitted and processed
in discrete blocks. But there is another method called "Convolutional
Coding". In this the parity bits and data bits are interwoven (often
alternately); the parity bits are formed from the exclusive-OR of selected
preceding data bits on a continuous basis.
INTERLEAVING
Bursts of noise are not uncommon on radio links, and coding schemes don't
like error bursts. So in many applications the data is interleaved just
prior to transmission. For example a 100 byte message could be sent in
byte order 0,10,20...90, 1,11,21...91, 2,12,22 .... 89,99, and re-ordered
upon reception. So a burst of channel errors is spread out in the re-
ordered block, making the decoder's job less arduous.
VOYAGER PROBES
More advanced systems use a mixture of a block codes, a convolutional code
and interleaving. Spectacular examples are the Voyager probes to the outer
planets, which achieve a 1 per million error rate at an Eb/No of only 2.53
db, as sketched in curve E of figure 1. This represents a coding gain of 8
db, a very substantial figure. The bandwidth expansion factor is 2.3:1
(ref 6, page 430).
SHANNON LIMIT
It is natural to ask if these improvements have a limit. The extraordinary
thing is that Shannon had already mathematically proved the fundamental
limit theorems, long before anyone had thought of building coding hardware!
(ref 2)
For the systems I've been discussing, in the power limited/bandwidth
unlimited situation, the ultimate is curve F in figure 1. When the SNR is
less than -1.6 db the error rate is 50%; above -1.6 db the error rate is
nil. (-1.6 db corrresponds to Ln2). Naturally to achieve the ultimate
system requires signal processing using an infinite amount of time and an
infinite amount of complexity! Nevertheless recent schemes have been
proposed which approach the Shannon limit within 1-2 db or so.
AMATEUR SATELLITE LINKS
Why is all this of interest for amateur satellites? Well, we can start by
looking at the performance limits of our current phase 3 type digital
links. Assume the spacecraft is limited to 1 watt e.i.r.p, and that the
range is 42000 km. Assume a realistic size of ground station antenna - say
18db gain on 70cm or a 1 metre dish on 13cm; assume also a realistic
receive noise level.
The maximum data rates achievable work out to around 600 b.p.s./watt on
70cm, and 350 b.p.s./watt at 13cm using PSK modulation and optimum
demodulation, at an error rate of 1 per million bits. Sufficient at
present for simple telemetry, but far short of our future needs.
THE VALUE OF CODING
Let's be ambitious; suppose we would like a throughput of 9600 bps on 70cm.
This is an increase of 16:1, or 12 db link improvement. Where is this
extra performance going to come from? The answer of course is from a
combination of a minimum increased transmitter power and a maximum of
coding gain. Coding gains of 5.5 db are probably realistic for amateurs,
so the transmit power would have rise to just 4.5 watts (6.5 db), instead
of a greedy 16 watts without coding.
Studies such as these are currently being performed by AMSAT. Indeed the
RUDAK-2 module carries additional experimental receivers and an RISC based
computer for fast signal processing. These will allow us to evaluate the
possibilities for new state of the art digital links for radio amateurs.
(On AO-21).
---------------------------------------------------------------------------
READING
1. Miller J.R.; "AO-13 Memories are made of this", AMSAT-UK Oscar News
No. 80, December 1989. See also [8].
2. Shannon C. E.; "Communication in the Presence of Noise", Proc. IRE,
vol 37, pp10-21, January 1949
3. Abramowitz M. and Stegun, I.; "Handbook of Mathematical Functions",
Dover Publications, 1965. ISBN 0-486-61272-4
4. Forney D.G.; "Coding and its Applications in Space Communications", IEEE
Spectrum, vol 7, pp 47-58, June 1970. (Excellent introduction).
5. Costas J.P.; "Poisson, Shannon, and the Radio Amateur", Proc. IRE,
vol 47, pp. 2058-2068, Dec 1959.
6. Haykin, S.; "Digital Communications", John Wiley and Sons 1988.
ISBN0-471-62947-2.
7. Posner E.C. and Stevens R.; "Deep Space Communication - Past Present and
Future", IEEE Communications Magazine, vol 22, pp 8-21, May 1984
8. Miller J.R.; "Down Memory Lane", AMSAT-UK Oscar News
No.108 August 1994 p16-19. Also: Amsat-VK Newsletter No. 112, 1994
Aug. Also: The Amsat Journal (USA) Vol 17 No. 5, Sep/Oct 1994.
Figure 1. Performance comparison of various channel coding schemes
A. Baseline: Binary PSK
B. (7,4) Hamming coding, hard decisions
C. (7,4) Hamming coding, soft decisions
D. Mariner '69 deep space probe, (32,6) bi-orthogonal coding
E. Voyager probes, NASA deep space standard (ref 6)
F. Theoretical Shannon limit on coding performance.
[ Added: In 2004 I discovered this Xilinx paper page 4.
[ Pirate copy - though admittedly pretty!]
HAMMING CODING
Now what happens when we add parity bits? Lets examine a specific
arrangement, the (7,4) Hamming code. In this, data is taken 4 bits at a
time and 3 parity bits appended to make a "word" of 7 bits, hence the
designation (7,4). I used this as my example in ref 1. Denoting the data
bits D0, D1, D2, D3, the parity bits are formed from excusive-ORs of the
data bits, viz: P0=D0+D1+D3, P1=D0+D2+D3, P2=D1+D2+D3. The 16 possible
words are thus (with a little space for clarity):
DDDD PPP DDDD PPP DDDD PPP DDDD PPP
3210 210 3210 210 3210 210 3210 210
--------------------------------------------------
0000 000 0100 110 1000 111 1100 001
0001 011 0101 101 1001 100 1101 010
0010 101 0110 011 1010 010 1110 100
0011 110 0111 000 1011 001 1111 111
--------------------------------------------------
Table 1. 16 code words of the (7,4) Hamming code
--------
So as an example, if the 4 data bits are 1100, P2=0, P1=0 and P0=1, so the
bits actually transmitted are 1100001 - see top of 4th column.
Consider transmission; we now send 7 bits in the time we would have sent 4
original ones. So the channel bit rate is 7/4 times what it was, implying
a 7/4x wider bandwidth.
Now reception; for the same transmitter power as used in the baseline
system, the received Eb/No must be 4/7 worse, leading to a higher error
rate for the 7 bits of the word. But the Hamming coding scheme allows
correction of up to 1 error. So words with 0 or 1 error are OK, words
with 2,3...7 errors are bad. Thus the probability of a word error is Pw =
p2+p3+p4+p5+p6+p7 = 1-(p0+p1), where p0 is the probability of nil errors,
p1 for 1 error and so on. When we get a word error, its data bits are
essentially garbage, i.e 50% are in error. So the equivalent bit error rate
for the system is approximately Pe=Pw/2 (actually 4/7*Pw).
Curve B of figure 1 shows the performance of the (7,4) Hamming code using
"Hard" decisions as described above, where the 7 elements of the word are
demodulated individually and independently. At an SNR less than 7.5 db
the baseline PSK system is a better performer, but above this SNR the
Hamming code wins. The gain is equivalent to 0.4 db in SNR at an error
rate of 1 per million.
CODING GAIN
Not dramatic, but it illustrates the point. We have achieved a
"coding gain" of 0.4 db at the expense of a) increased bandwidth,
b) increased decoder complexity and c) throughput delay.
This gain can be used either to a) reduce transmitter power or antenna
sizes by 0.4 db, or b) increase the data rate by 10%, or c) increase
communication range by 5%.
For reference, curve B is computed from the formulae:
p=0.5*erfc(sqr(4/7*Eb/No)), Pw=1-((1-p)7 + 7*p*(1-p)6), and Pe=Pw*4/7.
OPTIMUM DECODING
There is a better way to decode the 7 bit words. Instead
of demodulating them as 7 individual bits ("hard" decisions), we can
demodulate the whole word using 16 detectors individually matched to the 16
patterns in table 1. Then the detector showing the highest output or
"correlation" is chosen as correct and the associated 4 data bits are
output. This is called "soft" decision decoding. These detectors would
almost certainly not be mechanised in hardware, as there are so many of
them. It is far simpler to do the equivalent operations in software -
digital signal processing (DSP), though this need not concern us here; we
assume the job done somehow.
The performance of this new scheme, in which we appear to have forgotten
Hamming's error detection scheme, is shown in curve C of figure 1.
Compared with the baseline PSK, we have an improvement or coding gain of 2.
4 db at a bit error rate of 1 in a million. Now we're getting somewhere!
It's interesting to note that the performance difference between hard and
soft decision decoding, exemplified by this simple scheme, is just 2 db.
This hard/soft penalty, 10*log(PI/2), shows up regularly in signal
processing analysis, regardless of coding scheme, in the power-constrained
situation.
And no, we haven't really lost Mr Hamming. Remember there are 7 bits to
the word; that means a potential 128 combinations of bits, from which we
chose only 16. Not any 16, but a set in which each code-word is as
different as possible from each other word. Hamming's code achieves this,
as in fact do several other sub-sets.
MARINER '69 MARS PROBE
Mariner '69 Mars probe was one of the first missions to make use of coding.
Why? Because at vast distances, with limited transmitter power, a finite
antenna size on the spacecraft and on the ground, every fraction of a
decibel counts. Mariner '69 used a (32,6) code, in which blocks of 6 bits
were augmented to make a 32 bit word, a bandwidth expansion of 32/6 or 5.
3:1. Detection was by soft decisions using correlators. The performance is
shown in curve D of figure 1. The coding gain is about 3.6 db at an
error rate of 1 per million bits.
SOURCE CODING
Space probes typically send back images. However images are usually full
of redundant information. For example a picture that includes a horizon
might contain large areas of blackness. It would be a folly to send back
such an image without pre-processing.
The business of efficient representation of information is called "source
coding", as distinct from channel coding discussed so far. In many
applications, source coding is likely to have a far greater influence on
overall communications efficiency than channel coding, yet it is often
overlooked or simply ignored.
A good example is amateur spacecraft telemetry, where data is sent down
block after block, with little or no change in some of the data, but rapid
changes in others. So it's efficient for some information, but not all.
Another is plain language bulletins. When I checked a sample of 50 Oscar-
13 message blocks I found that based on the frequency of occurence of
letters/digits etc, the average Information content was less than 5
bits/character; yet we actually transmit bulletins with 8 physical
bits/character.
The most common symbol was 'space'. Clearly it could be represented by one
bit only, say 0. Next came the letter 'e', so it should be recoded as 10,
and so on. This kind of scheme is Huffman coding, an algorithm for the
construction of efficient signalling alphabets. In my example a saving of
5/8 in bits or 2 db would be achieved at the expense of a look-up table in
the spacecraft, and a similar algorithm at the receiver.
CONVOLUTIONAL CODING
Returning to the subject of channel coding; the schemes outlined thus far
are examples of "Block Coding", because data is transmitted and processed
in discrete blocks. But there is another method called "Convolutional
Coding". In this the parity bits and data bits are interwoven (often
alternately); the parity bits are formed from the exclusive-OR of selected
preceding data bits on a continuous basis.
INTERLEAVING
Bursts of noise are not uncommon on radio links, and coding schemes don't
like error bursts. So in many applications the data is interleaved just
prior to transmission. For example a 100 byte message could be sent in
byte order 0,10,20...90, 1,11,21...91, 2,12,22 .... 89,99, and re-ordered
upon reception. So a burst of channel errors is spread out in the re-
ordered block, making the decoder's job less arduous.
VOYAGER PROBES
More advanced systems use a mixture of a block codes, a convolutional code
and interleaving. Spectacular examples are the Voyager probes to the outer
planets, which achieve a 1 per million error rate at an Eb/No of only 2.53
db, as sketched in curve E of figure 1. This represents a coding gain of 8
db, a very substantial figure. The bandwidth expansion factor is 2.3:1
(ref 6, page 430).
SHANNON LIMIT
It is natural to ask if these improvements have a limit. The extraordinary
thing is that Shannon had already mathematically proved the fundamental
limit theorems, long before anyone had thought of building coding hardware!
(ref 2)
For the systems I've been discussing, in the power limited/bandwidth
unlimited situation, the ultimate is curve F in figure 1. When the SNR is
less than -1.6 db the error rate is 50%; above -1.6 db the error rate is
nil. (-1.6 db corrresponds to Ln2). Naturally to achieve the ultimate
system requires signal processing using an infinite amount of time and an
infinite amount of complexity! Nevertheless recent schemes have been
proposed which approach the Shannon limit within 1-2 db or so.
AMATEUR SATELLITE LINKS
Why is all this of interest for amateur satellites? Well, we can start by
looking at the performance limits of our current phase 3 type digital
links. Assume the spacecraft is limited to 1 watt e.i.r.p, and that the
range is 42000 km. Assume a realistic size of ground station antenna - say
18db gain on 70cm or a 1 metre dish on 13cm; assume also a realistic
receive noise level.
The maximum data rates achievable work out to around 600 b.p.s./watt on
70cm, and 350 b.p.s./watt at 13cm using PSK modulation and optimum
demodulation, at an error rate of 1 per million bits. Sufficient at
present for simple telemetry, but far short of our future needs.
THE VALUE OF CODING
Let's be ambitious; suppose we would like a throughput of 9600 bps on 70cm.
This is an increase of 16:1, or 12 db link improvement. Where is this
extra performance going to come from? The answer of course is from a
combination of a minimum increased transmitter power and a maximum of
coding gain. Coding gains of 5.5 db are probably realistic for amateurs,
so the transmit power would have rise to just 4.5 watts (6.5 db), instead
of a greedy 16 watts without coding.
Studies such as these are currently being performed by AMSAT. Indeed the
RUDAK-2 module carries additional experimental receivers and an RISC based
computer for fast signal processing. These will allow us to evaluate the
possibilities for new state of the art digital links for radio amateurs.
(On AO-21).
---------------------------------------------------------------------------
READING
1. Miller J.R.; "AO-13 Memories are made of this", AMSAT-UK Oscar News
No. 80, December 1989. See also [8].
2. Shannon C. E.; "Communication in the Presence of Noise", Proc. IRE,
vol 37, pp10-21, January 1949
3. Abramowitz M. and Stegun, I.; "Handbook of Mathematical Functions",
Dover Publications, 1965. ISBN 0-486-61272-4
4. Forney D.G.; "Coding and its Applications in Space Communications", IEEE
Spectrum, vol 7, pp 47-58, June 1970. (Excellent introduction).
5. Costas J.P.; "Poisson, Shannon, and the Radio Amateur", Proc. IRE,
vol 47, pp. 2058-2068, Dec 1959.
6. Haykin, S.; "Digital Communications", John Wiley and Sons 1988.
ISBN0-471-62947-2.
7. Posner E.C. and Stevens R.; "Deep Space Communication - Past Present and
Future", IEEE Communications Magazine, vol 22, pp 8-21, May 1984
8. Miller J.R.; "Down Memory Lane", AMSAT-UK Oscar News
No.108 August 1994 p16-19. Also: Amsat-VK Newsletter No. 112, 1994
Aug. Also: The Amsat Journal (USA) Vol 17 No. 5, Sep/Oct 1994.
Feedback on these pages to Webmaster.
Feedback on the article should be sent to James Miller
Page created: 1995 Jun 05 -- Last modified: 2023 Apr 18
{kind=link}